强制缓存和协商缓存?
HTTP 缓存可以分为协商缓存和强制缓存两种类型。
强缓存
强制缓存是指浏览器在请求资源时,不会发送任何请求头,直接从本地缓存中读取资源,从⽽提⾼响应速度, 只要浏览器判断缓存没有过期,则直接使用浏览器的本地缓存,决定是否使用缓存的主动性在于浏览器这边。

协商缓存
- 协商缓存是指浏览器在请求资源时,会发送⼀些请求头到服务器,询问服务器资源是否已经发⽣改变。如果资源未发⽣改变,服务器将返回 304 状态码,告诉浏览器可以从缓存中读取资源,从⽽减少了⽹络带宽的使⽤。强制缓存失效之后,浏览器在请求头中携带相应的缓存字段来向服务器发请求,由服务器根据这个字段,来决定是否使用缓存,这就是协商缓存。
1. 基于 Expires 字段实现的强缓存
使用响应头的Expires字段去实现强缓存
Expires 头部:指定资源过期的时间,如果在过期时间之前再次请求该资源,浏览器将直接从缓存中读取资源。
比如说将某一资源设置响应头为:Expires:new Date("2022-7-30 23:59:59");
那么,该资源在2022-7-30 23:59:59 之前,都会去本地的磁盘(或内存)中读取,不会去服务器请求。
Expires判断强缓存是否过期的机制是: 获取本地时间戳,并对先前拿到的资源文件中的Expires字段的时间做比较, 但是Expires过度依赖本地时间,如果本地与服务器时间不同步,就会出现资源无法被缓存或者资源永远被缓存的情况。
2. 基于 Cache-control 实现的强缓存
Cache-Control 头部:可以指定资源的缓存策略,包括 max-age, public、private、no-cache 等,控制浏览器的缓存⾏为。
通过在资源的响应头中设置 Cache-Control:max-age=N,N就是需要缓存的秒数。
那么, 从第一次请求资源的时候开始,往后N秒内,资源若再次请求,则直接从磁盘(或内存中读取),不与服务器做任何交互。
Cache-control中因为max-age后面的值是一个滑动时间,从服务器第一次返回该资源时开始倒计时。所以也就不需要比对客户端和服务端的时间,解决了Expires所存在的巨大漏洞。
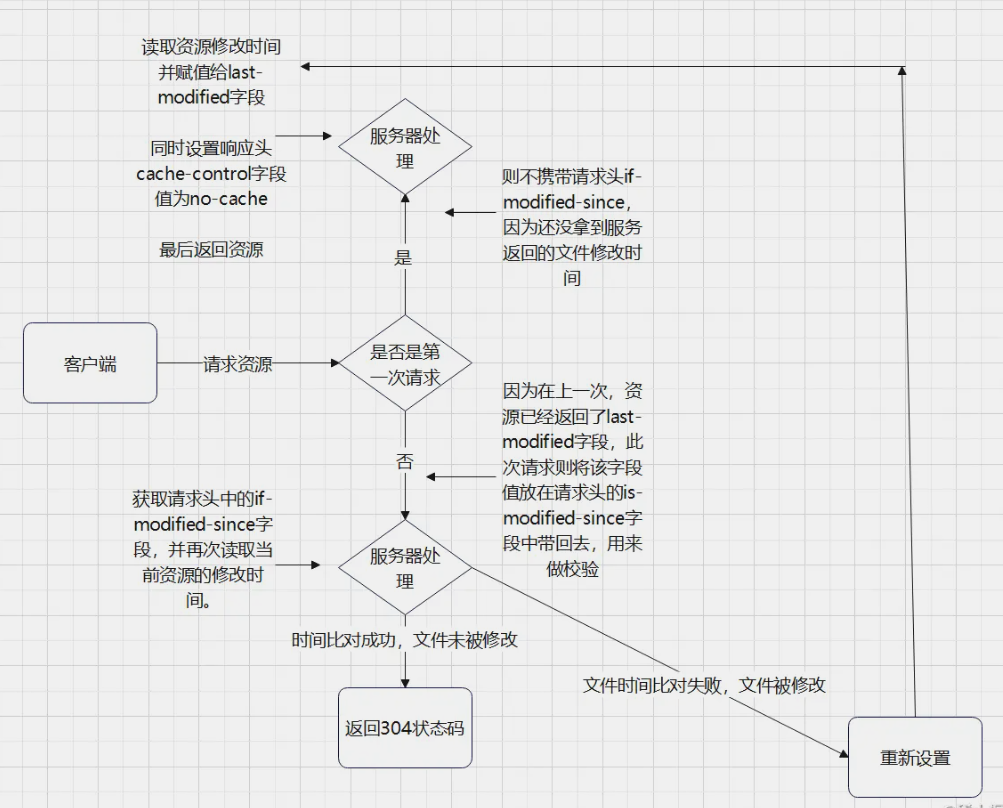
3. 基于 lasted-modified 实现的协商缓存
- 浏览器在第一次请求资源时,在服务器端读出文件修改时间,将读出来的修改时间赋给响应头的
last-modified字段。然后设置Cache-control:no-cache(跳过强缓存校验,直接进行协商缓存). - 当客户端读取到
last-modified的时候,会在下次的请求标头中携带一个字段If-Modified-Since(这个请求头中的If-Modified-Since就是上一次请求设置在响应头中的 last-modified)。 - 当再次请求资源时, 服务端需要拿到请求头中的
If-Modified-Since这个时间并再次读取该资源的修改时间, 让他们两个做一个比对来决定是读取缓存还是返回新的资源。如果没有发生变化,返回 304 状态码并读取缓存,否则返回新的资源并将资源修改时间赋值给响应头的last-modified字段。
使用以上方式的协商缓存存在两个非常明显的漏洞。这两个漏洞都是基于文件是通过比较修改时间来判断是否更改而产生的。
- 因为是更具文件修改时间来判断的,所以,在文件内容本身不修改的情况下,依然有可能更新文件修改时间(比如修改文件名再改回来),这样,就有可能文件内容明明没有修改,但是缓存依然失效了。
- 当文件在极短时间内完成修改的时候(比如几百毫秒)。因为文件修改时间记录的最小单位是秒,所以,如果文件在几百毫秒内完成修改的话,文件修改时间不会改变,这样,即使文件内容修改了,依然不会返回新的文件。
为了解决上述的这两个问题。从http1.1开始新增了一个头信息,ETag(Entity 实体标签)
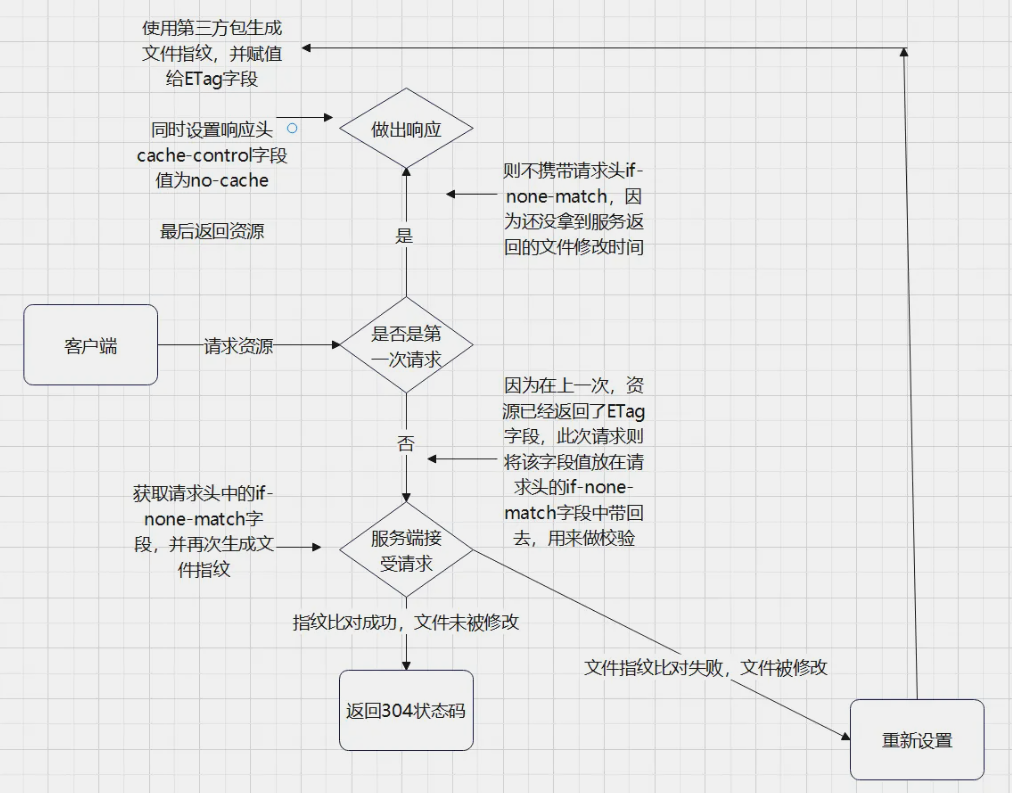
4. 基于 ETag 实现的协商缓存
- 第一次请求某资源的时候,服务端读取文件并计算出文件指纹,将文件指纹放在响应头的
etag字段中跟资源一起返回给客户端。 - 第二次请求某资源的时候,客户端自动从缓存中读取出上一次服务端返回的
ETag也就是文件指纹。并赋给请求头的if-None-Match字段,让上一次的文件指纹跟随请求一起回到服务端。 - 服务端拿到请求头中的
if-None-Match字段值(也就是上一次的文件指纹),并再次读取目标资源并生成文件指纹,两个指纹做对比。如果两个文件指纹完全吻合,说明文件没有被改变,则直接返回304状态码和一个空的响应体并return(这个时候已经读取了缓存)。如果两个文件指纹不吻合,则说明文件被更改,那么返回新的资源并将新的文件指纹重新存储到响应头的ETag字段
ETag 的缺点
- ETag需要计算文件指纹这样意味着,服务端需要更多的计算开销。。如果文件尺寸大,数量多,并且计算频繁,那么ETag的计算就会影响服务器的性能。显然,ETag在这样的场景下就不是很适合。
- ETag有强验证和弱验证,所谓将强验证,ETag生成的哈希码深入到每个字节。哪怕文件中只有一个字节改变了,也会生成不同的哈希值,它可以保证文件内容绝对的不变。但是,强验证非常消耗计算量。ETag还有一个弱验证,弱验证是提取文件的部分属性来生成哈希值。因为不必精确到每个字节,所以他的整体速度会比强验证快,但是准确率不高。会降低协商缓存的有效性。
5. 缓存位置
当强缓存命中或者协商缓存中服务器返回304的时候,我们直接从缓存中获取资源。那这些资源究竟缓存在什么位置呢?
浏览器中的缓存位置一共有四种,按优先级从高到低排列分别是:
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
Service Worker
Service Worker 借鉴了 Web Worker的 思路,即让 JS 运行在主线程之外,由于它脱离了浏览器的窗体,因此无法直接访问DOM。虽然如此,但它仍然能帮助我们完成很多有用的功能,比如离线缓存、消息推送和网络代理等功能。其中的离线缓存就是 Service Worker Cache。
Memory Cache 和 Disk Cache
Memory Cache指的是内存缓存,从效率上讲它是最快的。但是从存活时间来讲又是最短的,当渲染进程结束后,内存缓存也就不存在了。
Disk Cache就是存储在磁盘中的缓存,从存取效率上讲是比内存缓存慢的,但是他的优势在于存储容量和存储时长。稍微有些计算机基础的应该很好理解,就不展开了。
好,现在问题来了,既然两者各有优劣,那浏览器如何决定将资源放进内存还是硬盘呢?主要策略如下:
- 比较大的JS、CSS文件会直接被丢进磁盘,反之丢进内存
- 内存使用率比较高的时候,文件优先进入磁盘
Push Cache
即推送缓存,这是浏览器缓存的最后一道防线。它是 HTTP/2 中的内容,虽然现在应用的并不广泛,但随着 HTTP/2 的推广,它的应用越来越广泛。
6. 总结一下
- 需要注意的是,协商缓存虽然可以减少⽹络带宽的使⽤,但是需要服务器进⾏资源⽐较,会增加服务器的负载
- 关于强缓存,cache-control是Expires的完全替代方案,在可以使用cache-control的情况下不要使用expires
- 关于协商缓存,etag并不是last-modified的完全替代方案,而是补充方案,具体用哪一个,取决于业务场景。
- 有哈希值的文件设置强缓存即可。没有哈希值的文件(比如index.html)设置协商缓存
- 有些缓存是从磁盘读取,有些缓存是从内存读取,有什么区别?答:从内存读取的缓存更快。
- 所有带304的资源都是协商缓存,所有标注(从内存中读取/从磁盘中读取)的资源都是强缓存。